
We are delighted to lead Scribble Data’s pre-series A round, and to partner with the team in their journey to build a cloud native modularized feature store integrated with feature apps that drive end-to-end ML use cases. Scribble Data is building a cutting edge deep tech product that solves a fundamental problem for companies that want to leverage their data to drive value for their business. Our conviction in the company was built primarily on the scale of the market opportunity, a unique product approach towards a nascent category, great traction showing early signs of PMF, and a lean team with deep expertise to build a world class MLOps product.
Market Opportunity – Every company is becoming a data company, and Scribble is enabling that.
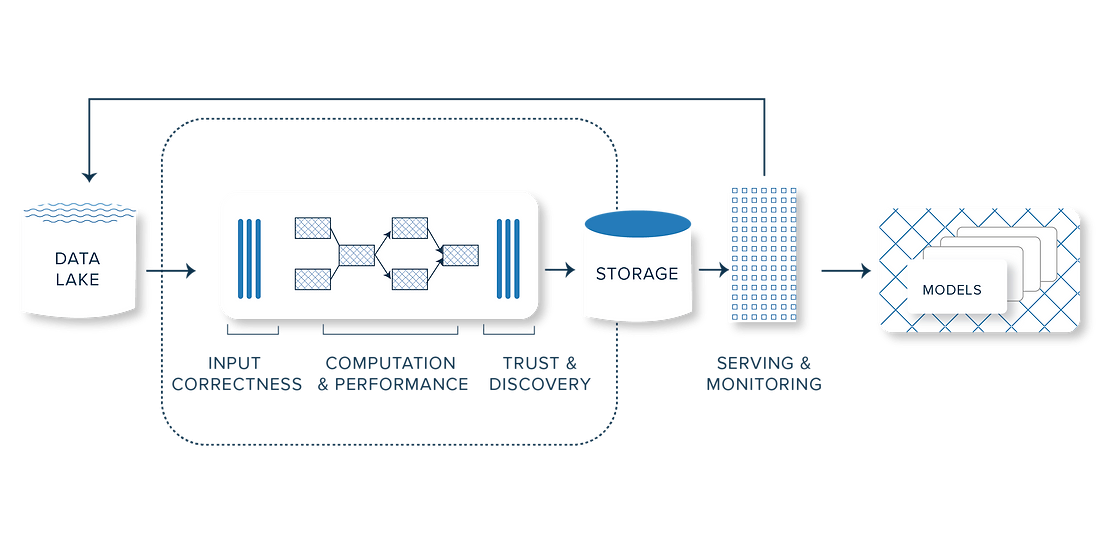
We strongly believe that all the tooling we have seen being built in the DevOps space will play out with even more complexity and at a greater magnitude in the MLOps space given the dual emphasis on deploying an increasing number of ML models and doing so with confidence in how they perform over time. Over the last few years, we have witnessed the emergence of a new generation of MLOps startups that have launched exciting products catering to different needs in the ML workflow. Setting up an efficient data stack to expedite the time-to-deployment of ML models as well as sub ML use cases has now become table stakes for companies.
A core problem in this segment has been the constant need to build and maintain features for every ML model or sub ML use case – This involves complex transformations across multiple data sources, serving the features to the right consumption interfaces, tracking data lineage, measuring drift in data/models, etc., and all of these activities eat into the time of data scientists/data engineers which can be utilized in more value additive activities. Enterprises across sectors are now forced to think like data companies. Considering the volume of data generated by these enterprises and how this data often resides in silos, feature stores have the ability to become powerful tools that can enable the democratization of machine learning across the organization.
Uniqueness of Scribble Data’s Feature Store – Modularized approach with feature engineering apps to slot into customers’ existing data stack, and streamline feature engineering in their individual contexts
Beyond the market, what got us further excited about Scribble was the modularized app store that is being built atop the Enrich feature store. With modularity built into the heart of the product, Enrich will provide data scientists with a powerful low code configurable interface that will allow them to create their own custom workflows for their feature-engineered datasets. The feature apps service multiple functionalities ranging from metadata management and data cataloging to a metrics app that enable companies to search and store KPIs and metrics they are tracking across the organization. The modularity, flexibility and ease of development of a range of use cases that Scribble Data offers are among their biggest differentiators in comparison to other companies in this space. These attributes match well with what customers are highlighting to us as their needs – low time to value, more use cases, and better utilization of talent and data.
Traction and early signs of PMF – Scribble has clients across NA, EU, and Asia, and has achieved significant revenue with high capital efficiency
In this new avatar of a feature app store, the team is already seeing significant traction from global customers in fintech, social networking, e‑commerce and healthcare, with the ARR tripling in the past year. In addition, the team has been instrumental in etching a collaboration with Redis labs to take them to market. What was more impressive to us was that all of the product and GTM traction had been achieved with minimal funding of $150K. The focus on value added to customers, building tech that caters to the core needs of the target ICP, and a great culture resulted in high customer engagement, capital efficiency, and a product that can deliver growth. Dozens of North American customers surveyed in Q4 2021 helped zero in on the ideal customer profile and GTM strategy which would enable Scribble to effectively deploy the capital raised in this round into activities that would help them achieve scale efficiently.
Global team with deep technical and GTM expertise – Both Venkata and Indra have played key data science roles at large organizations as well as startups over the last decade
When we first met Scribble Data’s founders Indrayudh Ghoshal and Venkata Pingali, we saw a perfect blend of deep technical expertise, first principles thinking, and on-ground data science experience, that enabled them to understand the pain points of modern day enterprises. What was more interesting was that in Scribble Data’s initial years they had set out to address the lack of trust in data preparation and deployment, and then narrowed their focus to feature engineering in 2019 – We believe those initial years of the company has been super helpful for the team to understand the core problems that the end users face. Scribble Data has a dual presence in North America and India which has enabled a global perspective for the company. With Indra based out of Toronto post this round, we are very excited about the team in Toronto scaling up, and believe being local in North America will bring in significant GTM advantages for Scribble Data.

With this round, there will be a focus on growing the lean team across sales, tech and marketing in India and North America while doubling down on the traction seen in the North American market. We are delighted to partner with Scribble Data in their journey towards becoming the marketplace of choice for feature engineering needs, akin to what Github Actions has become for all software workflows, and have complete confidence in the team’s ability to build a world class MLOps company.
Topics
Startups


Scribble Data
Active investmentScribble Data is an MLOps product company, which provides foundational blocks on which enterprises build their ML models and analysis. Their modular feature store, Enrich, comprises a number of pre-built feature engineering apps to help…- Current Section
- Portfolio
- Sector
- Infrastructure SaaS & Dev Tools, Horizontal SaaS
Funds
Fund IV
Blume is presently investing out of Fund IV (2021 onwards). Fund IV is our largest fund at ~$290M. Early breakouts include EV player Battery Smart and exporter SaaS Sourcewiz.- Number of startups
- 35 startups
- Years
- -